IMC(In-Memory Computing)とは何か:動作原理から回路方式、精度設計の考え方まで
In-Memory Computing(IMC)は、メモリ内部で直接計算を行いデータ転送の遅延と消費電力を削減する技術です。電気的原理を利用した演算の仕組みから、SRAM等の回路方式、AI処理での利点と精度設計の課題まで詳しく解説します。
In-Memory Computing(IMC)とは何か
In-Memory Computing(IMC)は、データを保存するメモリの内部またはその近傍で直接計算処理を行うアーキテクチャです。プロセッサとメモリが分離した従来の構造では、演算のたびにデータを読み出す必要がありましたが、IMCはデータ移動を極限まで削減し、AI処理や大規模データ処理における圧倒的な電力効率とスループットの向上を実現します。
従来コンピュータにおけるノイマンボトルネック
現在の多くのシステムは、プロセッサとメモリが分離したノイマン型アーキテクチャを採用しています。この構造では、演算に必要なデータをDRAMやSRAMからCPU/GPUへ転送し、処理後に再び書き戻す物理的なデータ移動が頻繁に発生します。大規模なパラメータを扱うAI処理では、演算そのものよりもメモリ間のデータ転送に数十倍から数百倍のエネルギーと時間を消費します。この「ノイマンボトルネック(メモリの壁)」は、近年の半導体微細化の限界と相まって、システム全体の消費電力とレイテンシを悪化させる最大の要因となっています。
In-Memory Computingの基本コンセプト
IMCの基本的なアプローチは、データを保存しているメモリアレイの物理法則をそのまま演算ロジックとして活用することです。ワード線を同時に複数活性化し、メモリセルからビット線へ出力される信号の重なりを読み取ることで、プロセッサへデータを移動させることなく「その場」で加算や積和演算を完了させます。これにより、外部バスの帯域幅制限を根本的に回避し、アレイが持つ巨大な内部バス幅をフル活用した超並列処理が可能になります。データ移動中心の従来アーキテクチャから、データ滞在型の計算パラダイムへの転換を意味します。
AI・データ処理でIMCが注目される理由
近年、Transformerなどの大規模言語モデル(LLM)の登場により、AI推論に必要なメモリ帯域幅は指数関数的に増大しています。ニューラルネットワークの処理は、入力ベクトルと重み行列を掛け合わせる巨大な行列演算(MAC演算)で構成されており、重みデータをいかに高速かつ省電力で供給するかが性能の律速となります。IMCは重みデータを固定したメモリセルに対し、入力信号を一斉に流し込むことで、O(1)の時間計算量で多数のMAC演算を実行できます。この究極のエネルギー効率が、エッジAIハードウェアのブレイクスルーとして期待される理由です。
IMCの動作原理
IMCは、デジタル論理ゲートによる逐次的な計算手法を捨て、メモリ回路の電気的・物理的な振る舞いを計算資源として利用します。電圧や抵抗値、そして配線上で合流する電流の性質といった電気的な基本原理を直接演算に生かし、複数のセルから出力される電流や電圧をビット線上で合成することで、高密度な行列演算を一度のサイクルで完了させる独自の原理を持ちます。
メモリアレイ内で演算を行う仕組み
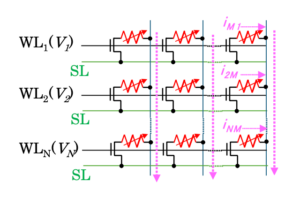
通常のメモリ読み出しでは、1つのワード線を立ち上げて1行分のデータを読み出しますが、IMCでは複数のワード線を同時に駆動(マルチワードライン・アクティベーション)します。例えば、各メモリセルが持つコンダクタンスに対して、ワード線から入力電圧を印加すると、電圧とコンダクタンスの積に比例した電流が各セルに流れます。これらのセルが共通のビット線に接続されていれば、配線の合流点において各セルからの電流が自然に足し合わせられるため、結果として一括で積和演算が物理的に実行されます。これがメモリアレイを利用した演算の基礎となります。
行列演算(MAC)とニューラルネットワーク処理
ニューラルネットワークの推論処理の9割以上は、積和演算(Multiply-Accumulate: MAC)が占めています。IMCのアーキテクチャはこのMAC演算に特化して最適化されています。ネットワークの「重み」を各メモリセルの導電状態としてあらかじめ書き込んでおき、「入力ベクトル」をDAC(D/Aコンバータ)を介してアナログ電圧としてワード線へ並列入力します。すると、ビット線の終端には入力と重みの積和結果に比例したアナログ電流が流れ出ます。これをADC(A/Dコンバータ)でデジタル値に変換し、次段の層へ渡すことで推論が進行します。
電流加算・電圧加算による演算原理
演算の物理的な実装方法には、主に電流モードと電圧モードが存在します。電流加算方式は、前述のようにビット線上で電流を束ねる方式であり、高速かつ直感的に積和演算を実装できますが、セル数が増えると配線抵抗による電圧降下が演算精度を劣化させます。一方、電圧加算(電荷共有)方式は、メモリセルに直列接続したキャパシタの電荷をビット線上で再分配することで平均電圧を得る手法です。こちらは定常的な貫通電流がないため静的消費電力を極めて低く抑えられますが、寄生容量の影響を受けやすく設計難易度が上がります。
IMCの主な回路方式
IMCの回路実装は、演算結果をデジタル・アナログのどちらで処理するか、および基盤となるメモリ素子(揮発性/不揮発性)の選択によって大きく分類されます。既存のCMOSプロセスと親和性の高いSRAMベースの方式と、高密度実装が可能な次世代不揮発性メモリを用いたクロスバー方式が、現在のアプローチの双璧をなしています。
デジタルIMC(SRAMベースIMC)
デジタルIMCは、標準的なSRAMを拡張し、セル内部やビット線周辺に算術論理演算器(ALU)などの微小なロジックを組み込む方式です。複数セルの論理演算(AND, NOR等)をビット線上で評価し、その結果を加算器ツリーで集計します。一般的な6トランジスタ(6T)構成では読み出し時の電圧変動によってデータが意図せず反転・破壊される危険があるため、読み出しポートを分離した8Tや10Tのセル構造が採用されます。アナログ方式と比べて演算密度は低下しますが、ノイズやプロセスばらつきに強く、高い演算精度(8ビット〜16ビット以上)を安定して確保できるのが利点です。
アナログIMC(クロスバー型IMC)
アナログIMCは、配線の交点(クロスポイント)に抵抗変化型素子を配置するクロスバーアレイ構造を利用します。1つのメモリ素子がそのまま1つのシナプス(重み)として機能するため、SRAMベースに比べて圧倒的な高密度実装が可能です。一度のクロックでアレイ全体のMAC演算を瞬時に完了できるためピーク性能は極めて高くなります。しかし、アナログ電流をデジタルに戻すためのADCがビット線ごとに必要となり、このADC周辺回路の面積と消費電力がアレイ本体を上回ってしまう「ADCボトルネック」が実用化における最大の壁となっています。
IMCに利用されるメモリ技術とその特徴
IMCの心臓部となるメモリデバイスには、それぞれ一長一短があります。SRAMは現在のシリコンプロセスで即座に量産可能で高速ですが、面積が大きく電源断でデータが消滅します。一方、ReRAM(抵抗変化型メモリ)やPCM(相変化メモリ)は多値記憶が可能で高密度ですが、書き込み時のばらつきに課題があります。また、強誘電体を利用したFeRAM(FRAM、強誘電体メモリ)は、電圧駆動による低消費電力書き込みと高い耐久性を併せ持ち、次世代エッジAI向けの不揮発性IMC素子として本命視されています。要件に合わせて適切なメモリ素子を選択することが設計の第一歩です。
IMC技術のメリットと今後の展望
データ転送の壁を突破するIMCは、半導体の微細化ペースが鈍化しつつある現代において、システム性能を飛躍させる切り札です。エッジデバイスでの自律的なAI処理を実現する一方で、アナログ特有の不完全さをいかにシステムレベルで吸収するかが、研究開発から量産へのフェーズを移行するための重要な鍵を握っています。
IMCがもたらす消費電力と性能のメリット
プロセッサ外部のDRAMからデータを取得するエネルギーは、ALUで1回のMAC演算を行うエネルギーの約200倍に達します。IMCはこの外部メモリアクセスを根絶することで、システム全体の消費電力を数十分の一から数百分の一にまで削減します。単位電力あたりの演算性能(TOPS/W)という指標において、従来のデジタルアクセラレータが数TOPS/Wで頭打ちになる中、アナログIMCは数十〜数百TOPS/Wという破壊的な電力効率を叩き出します。これにより、バッテリー駆動の監視カメラやウェアラブル機器への高度なAIモデルの実装が現実のものとなります。
実用化に向けた技術課題(精度設計など)
アナログIMCの実用化を阻む最大の要因は「演算精度の低さ」です。温度変化、電源電圧の揺らぎ、半導体製造時の微細な形状ばらつきによって、同じ重みを書き込んでも出力される電流値が変動します。一般的にアナログIMCの演算精度は4〜8ビット程度が限界とされ、高精度が求められる学習処理には不向きです。そのため、ハードウェアのばらつきを前提としてAIモデル側を再学習させる「Hardware-Aware Training」や、デジタル回路で誤差を補正するハイブリッドアーキテクチャなど、ソフトウェアと協調した精度設計が不可欠です。
次世代メモリ技術とIMCの将来性
現在のIMC研究はSRAMベースの実証チップから、不揮発性メモリを用いた商用化フェーズへと移行しつつあります。特にMRAMやFeRAMを活用した不揮発性IMCは、電源を落としてもAIモデルの重みが保持される「ノーマリーオフ・コンピューティング」を実現し、間欠動作が基本となるIoTエッジ端末の待機電力を実質ゼロにします。さらに今後は、最新のパッケージング技術と組み合わせ、ロジックダイの直上にIMCメモリダイを積層する3D-IMCへの進化が見込まれており、メモリと演算が完全に融合した究極のコンピューティング形態へと発展していくでしょう。
RAMXEEDが提供するFeRAM製品一覧
https://www.ramxeed.com/jp/products/feram-products