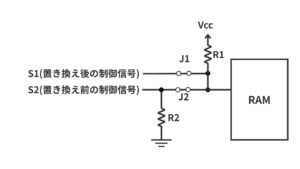
SPI SRAM高速化の設計手法完全ガイド|QSPI対応・メモリ変更まで徹底解説
SPI SRAMの高速化設計について、通信最適化の基本からQSPIによるインターフェイス拡張、FeRAM(FRAM、強誘電体メモリ)へのメモリ変更までを体系的に解説します。設計現場で求められる性能向上の考え方と、実践的な検討ポイントを分かりやすく整理しています。
目次
SPI SRAM高速化の基本設計アプローチ
SPI SRAMの高速化を検討する際は、単純なクロック周波数の向上だけでなく、通信効率や遅延要因を含めた総合的な設計最適化が欠かせません。特にスループットとレイテンシの関係を正しく理解し、ハードウェアとソフトウェアの両面からボトルネックを特定する視点が求められます。
SPI通信におけるスループットとレイテンシの基礎理解
SPI通信の性能はクロック周波数のみで決まるものではなく、コマンド送信、アドレス指定、ダミーサイクル、チップセレクト制御など複数のオーバーヘッド要素が影響します。特に小容量データを頻繁に扱う場合、これらの固定コストが支配的となり、理論値よりも実効スループットが大きく低下します。たとえば数十バイト単位の細かいランダムアクセスを繰り返す制御では、この通信ロスがシステム全体の致命的な遅延になり得ます。したがって、レイテンシはリアルタイム処理に直結するため、帯域だけでなく応答時間やジッタも考慮し、通信パターンに応じた最適化を図ることが重要です。
通信プロトコル最適化による実効帯域の向上
SPI SRAMの性能を引き出すには、通信プロトコルの最適化が不可欠です。連続アドレスアクセスによるバースト転送を活用することで、アドレス指定の回数を削減し効率を大幅に向上させます。さらに、マイコン内蔵のSPI周辺回路が持つ自動アサート機能などを併用し、ソフトウェア処理が介在する隙間を極力減らすアプローチも非常に有効です。また、不要なコマンドの削減やチップセレクト信号の制御最適化により転送間の待ち時間を抑え、データ転送のパイプライン化によってコマンドとデータ処理を重ねることで、実効帯域の最大化が実現します。
高速動作を支える基板設計と信号品質対策
高速SPI通信では基板設計と信号品質が重要な要素です。配線長のばらつきやインピーダンス不整合は反射や波形劣化を引き起こし、誤動作の原因となるため、配線の等長化や適切な終端処理、インピーダンス管理が必須となります。特に50MHzを超えるような高周波領域では、クロック波形のなまりやオーバーシュートがデータの取りこぼしに直結しやすくなります。また、グラウンド設計や電源デカップリングの最適化でノイズ耐性を高め、クロック信号の品質を維持することが、高周波領域での安定した高速動作に直結します。
SPI SRAMで実現する高速化の具体的手法
SPI SRAMを用いた高速化では、デバイス選定と制御設計の両面からの最適化が不可欠です。単に高クロック対応品を選ぶだけでなく、連続アクセス機能や内部動作仕様を深く理解し、ホスト側の制御と適切に組み合わせることで実効性能を最大化できます。
高速対応SPI SRAM選定時に確認すべき仕様
SPI SRAMを選定する際は、最大動作周波数だけでなく、連続読み出しモードの有無やダミーサイクル数、ページサイズといった仕様の詳細な確認が重要です。特に連続読み出し機能を備えたデバイスは、コマンドやアドレス送信の回数を削減できるため、通信効率が劇的に改善します。また、高速動作時の安定性を左右するI/O駆動能力やタイミングマージンに加え、動作電圧範囲や温度特性も含めて総合的に評価することで、過酷な実環境でも安定した高速通信を確保できます。
ホスト側(MCU/FPGA)制御最適化の実践ポイント
SPI SRAMの性能はホスト側の制御設計に大きく依存します。DMAを活用してCPU介在を最小限に抑えながら連続データ転送を実現し、処理効率を飛躍的に高める手法が有効です。また、FIFOの適切な利用でデータ供給の途切れを防ぎバス効率を向上させるほか、チップセレクト信号の不要なトグルを削減して転送間の待ち時間を排除します。クロック設定や転送サイズ、割り込み制御の調整も含め、システム全体を俯瞰した最適化が求められます。
ボトルネック分析と性能チューニング手法
高速化を実現するためには、実際の通信挙動を可視化し、ボトルネックを定量的に特定することが不可欠です。ロジックアナライザでSPI信号を観測すれば、コマンド送信間のギャップやアイドル時間といった非効率な部分を明確に把握できます。実効転送効率を数値化して理論値との乖離を分析し、パラメータ変更による効果を比較検証することで、改善ポイントと最適な設定を導き出します。この分析と改善のサイクルを回すことが、システム全体の性能底上げにつながります。
QSPI SRAMなどインターフェイス変更による高速化戦略
SPI SRAMの性能向上には、通信方式そのものの見直しも有効な手段です。従来のSingle SPIが抱える帯域の限界に対し、データラインを拡張したインターフェイスを採用することで、同一クロックでも大幅なスループットの向上が見込めます。
Single SPIとQSPIの帯域差と理論性能比較
Single SPIが1ビット幅でデータを転送するのに対し、QSPIは4ビット同時転送を行うため、理論上は同一クロック条件で4倍の帯域を確保できます。この違いは大容量データの連続転送において顕著に現れ、通信時間の大幅な短縮に直結します。ただし、実際のシステムではコマンドフェーズやダミーサイクルの影響を受けるため、単純に4倍の性能が得られるわけではありません。実効速度の評価には、データフェーズの比率やアクセスパターンを踏まえた慎重な検討が求められます。
QSPI SRAM導入時の設計変更ポイント
QSPI SRAMの導入時には、信号線の増加に伴う設計変更が必須となります。データラインの複数化により配線密度が高まり信号品質の確保が難しくなるため、より高精度なレイアウト設計が求められます。スキューやクロストークを抑えるための配線長管理や層構成の検討に加え、ダンピング抵抗の適切な配置など、シグナルインテグリティ(信号品質)を確保する対策も不可欠です。ホスト側コントローラのQSPI対応状況の確認と、動作モード・タイミング条件の適切な調整を行うことで、高速化と安定動作の両立が実現します。
Octal SPIや他高速インターフェイスとの比較
さらなる高速化を求める場合、Octal SPIやHyperBusなどのインターフェイスも有力な検討対象です。Octal SPIは8ビット同時転送によりQSPIを凌駕する帯域を実現しますが、ピン数の増加や設計難易度の上昇といった課題も伴います。一方のHyperBusは高スループットと低レイテンシを両立するものの、対応デバイスやコントローラに制約が存在します。用途に応じた性能、実装コスト、設計負荷の総合的な評価が欠かせません。
メモリ変更による高速化戦略 ― FeRAM活用の可能性と評価
SPI SRAMの高速化には、インターフェイスの改善だけでなく、メモリそのものを変更するアプローチも非常に有効です。特に書き込み特性やレイテンシに課題を抱えている場合、別種メモリの採用がシステム全体の性能を根本から改善するブレイクスルーになり得ます。
SPI SRAMの構造的制約と性能限界
SPI SRAMは高速な読み書きが可能な反面、シリアル通信特有の構造的な制約を抱えています。コマンド送信やアドレス指定のオーバーヘッドは避けられず、特にランダムアクセスや短いデータ転送の反復では著しく効率が低下します。加えて、書き込み動作時に内部動作に起因する待ち時間が発生するケースもあり、リアルタイム性が要求される用途では致命的なボトルネックとなる恐れがあります。こうした制約を理解したうえでのシステム要件の評価が不可欠です。
FeRAMを用いた高速化の技術的メリット
FeRAMは強誘電体を利用した不揮発性メモリであり、書き込み動作において待ち時間がほとんど発生しないという最大の強みを持ちます。この特性から、ランダムアクセス性能や低レイテンシが求められる用途で圧倒的な優位性を発揮します。マイコン側で完了待ちのループ処理や複雑なステートマシンを組む必要がなくなるため、ファームウェア設計の大幅な簡略化にも貢献します。さらに、実質無制限の高い書き換え耐久性と低消費電力動作を兼ね備えており、従来のSPI SRAMでは対応が困難だった電源喪失時のデータ保持やシステムのバッテリーレス化などシビアなシステム要件に対する新たな設計の選択肢となります。
QSPI対応のFeRAMによる更なる高速化
FeRAMにはQSPI対応製品も登場しており、従来のシングルSPI接続と比べてデータ転送帯域を大幅に拡張できます。FeRAM特有の低レイテンシと書き込み待ち時間ゼロの特性を維持したまま連続転送時のスループットを向上できるため、大容量データのストリーミング処理や高速ログ記録において絶大な相乗効果を生み出します。一方で、ピン数増加に伴う設計の複雑化や対応コントローラの制約といった要素も存在するため、性能向上効果と実装負荷のバランスを踏まえた慎重なシステム設計が求められます。
RAMXEEDのQuad SPI対応 FeRAMファミリ
https://www.ramxeed.com/jp/product_detail/s-1/